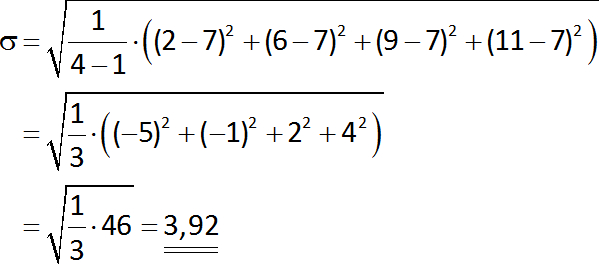I denne formel betegner n1 og n2 størrelsen af stikprøven fra hhv. population 1 og population 2, X1 og X2 betegner gennemsnittet på stikprøven fra hhv. population 1 og population 2. Sp betegner den poolede standardafvigelse (den ”fælles” standardafvigelse, som er en slags gennemsnitlig standardafvigelse for stikprøverne). Den beregnes efter ovenstående formel ud fra S1 og S2, som er standardafvigelsen for stikprøven for hhv. population 1 og population 2. Igen er t den parameter, der bestemmes. Bemærk, at antallet af frihedsgrader nu beregnes efter en ny formel. Et eksempel på hvordan en t-test for to gennemsnit benyttes, er givet i eksempel 8.
Konfidensinterval
Et sidste statistisk begreb, der vil blive præsenteret i denne artikel, er konfidens-intervallet. Konfidensintervallet benyttes til at udtrykke, at et gennemsnit for nogle data med en given sikkerhed ligger inden for et interval (f.eks. at gennemsnittet for antallet af æbler på et æbletræ med 90 % sandsynlighed ligger mellem 100 og 200). Til at lave et konfidensinterval benyttes mange af de samme parametre som ved t-test, og ofte laves der et konfidensinterval efter en t-test er udført. Formlen for konstruktionen af et konfidensinterval er givet ved:
Ligning 6: konfidensinterval for middelværdien
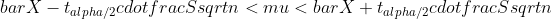
Antal frihedsgrader: v = n – 1
Her betegner n størrelsen af stikprøven, X betegner gennemsnittet på stikprøven, μ betegner hele populationens gennemsnit, S betegner standardafvigelsen for stikprøven, og tα/2 er en t-parameter, der slås op i en t-tabel ud fra valg af α og antallet af frihedsgrader. Et eksempel på, hvordan et konfidensinterval beregnes, er givet i eksempel 9.
En vigtig pointe ved konfidensintervaller er, at når et sådant interval er beregnet, kan man udelukke alle værdier, som ikke indgår i intervallet med den givne procents sikkerhed. Dvs. hvis man startede med at udregne konfidensintervallet fra eksempel 9, kunne man hurtigt konkludere, at gennemsnittet for hele populationen med 95 % sikkerhed ikke er 10 (som det blev vist i eksempel 7). Det kan derfor være en stor fordel at udregne et konfidensinterval for et gennemsnit, når man har taget en stikprøve. Man kan så, uden at skulle lave mange t-tests, hurtigt afvise alle værdier, der ikke ligger inden for intervallet.
For sammenligning af to gennemsnit kan et konfidensinterval også benyttes. I dette tilfælde er konfidensintervallet givet ved følgende formel:
Ligning 7: Konfidensinterval for forskellen på to gennemsnit
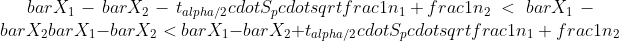
Hvor
cdot&space;S_%7B1%7D%5E%7B2%7D&space;+&space;(n_%7B2%7D-1)cdot&space;S_%7B2%7D%5E%7B2%7D&space;%7D%7Bn_%7B1%7D+n_%7B2%7D-2%7D%7D)
Antal frihedsgrader: v = n1 + n2 – 2
I denne formel betegner n1 og n2 størrelsen af stikprøven fra hhv. population 1 og population 2, X1 og X2 betegner gennemsnittet på stikprøven fra hhv. population 1 og population 2. Sp betegner den poolede standardafvigelse. Den beregnes efter ovenstående formel ud fra S1 og S2, som er standardafvigelsen for stikprøven for hhv. population 1 og population 2. Størrelsen tα/2 er en t-parameter, der slås op i en t-tabel ud fra valg af α og antallet af frihedsgrader. I eksempel 10 kan det ses, hvordan et konfidensinterval for forskellen på to gennemsnit kunne have været benyttet til nå til samme konklusion som i eksempel 8.
Relation til biologien
Statistik benyttes som redskab i mange fag. I biologien benyttes statistik specielt i forbindelse med udvikling af lægemidler, fastsættelse af biologiske parametre ud fra eksperimenter og sandsynliggørelse af biokemiske teorier. Bl.a. er statistik en fuldstændig nødvendighed for gennemførelsen af målinger med DNA-mikroarrays, hvor der typisk køres forsøg med forskellige typer celler. Da det er umuligt at teste alle kræftceller i en bestemt kræftsygdom i et DNA-mikroarray, endsige bare i en enkelt tumor, er det nødvendigt at kunne gennemføre pålidelige forsøg, som kan generalisere udfaldet af få eksperimenter til teorier og hypoteser omkring kræftudvikling og kræftbekæmpelse. Hertil bidrager statistikken, ved at den med en vis procents sikkerhed kan estimere værdien af en parameter (ofte inden for et konfidensinterval) ud fra stikprøver af hele cellepopulationer. I forbindelse med biologiske forsøg accepteres det generelt, at konklusionerne på forsøgene kun er 95 % sikre (f.eks. i en t-test med α-værdi på 5 %, eller et konfidensinterval på 95 %), men undertiden i strenge medicinske forsøg kan kravene til sikkerhed være endnu højere (ofte 99 % sikkerhed). Det er naturligvis altid sværere at påvise en sammenhæng eller estimere en værdi, hvis kravene til sikkerheden i resultatet forøges. Derfor er det normalt at kræve, at ens resultat er mellem 95 % og 99 % sikkert. Dette krav giver et relativt pålideligt resultat, samtidig med at denne afvigelse fra 100 % sikkerhed giver en enorm tidsbesparelse. En mindre stikprøve på nogle tusind kræftceller vil ofte være nok (såfremt stikprøven er repræsentativ!) til f.eks. at vurdere med 95 % sikkerhed, om kræftcellerne har en højere produktion af et givent protein ift. raske celler. Dette må mildt sagt siges at være lettere end at teste samtlige celler i en menneskekrop.
Til sidst bør det siges, at statistikken også har sine faldgruber. Ofte vil man gerne vise sammen-hænge (statistisk kaldt: at korrelere forsøgsresultater), men det kan undertiden være muligt at se statistiske sammenhænge mellem fænomener, som ikke er beslægtede. Det er f.eks. sandsynligt, at der ville kunne ses en sammenhæng mellem hudkræft og havbadning. Dette skyldes selvfølgelig ikke, at det at bade i havet er kræftfremkaldende. Derimod kunne det skyldes, at de personer, som bader i havet, sandsynligvis også er personer, som befinder sig meget i solen, og som derfor modtager en stråling, der kan være årsag til kræftudvikling. Det er derfor altid vigtigt nøje at overveje de sammenhænge og resultater, man vil prøve at vise, og være kritisk i ens analyse.